
Picture this: a global retailer with stores across Asia, Europe, and the Americas. Their inventory and ordering system was built in the early 2000s. It still works — mostly. But every Black Friday or major sales event turns into a white-knuckle ride. The system slows to a crawl, orders get lost in limbo, and the operations team spends the next week manually reconciling data. Meanwhile, nimbler competitors launch same-day delivery features and real-time stock visibility without breaking a sweat.
This isn’t a rare story. It’s playing out in banks, manufacturers, insurers, governments, and healthcare providers on every continent. Legacy applications — the ones that have quietly powered businesses for 10, 15, or even 25 years — are no longer just technical debt. They’re a competitive liability, a growing security risk, and a brake on the kind of innovation customers now expect as standard.
Application modernization is the deliberate process of transforming these systems so they can support how organizations actually need to operate today and tomorrow. It’s not about chasing the newest technology for its own sake. It’s about aligning software with business goals: faster response to market changes, lower operating costs, better resilience, easier integration with partners and AI capabilities, and the ability to attract and keep good technical talent.
In 2026, the pressure is higher than ever. Regulatory demands are tightening worldwide. AI and real-time data processing are moving from nice-to-have to table stakes. Cloud economics keep improving, while the cost of maintaining aging on-premises or monolithic systems keeps rising — both in money and in opportunity. The organizations pulling ahead aren’t necessarily the ones doing the most dramatic rip-and-replace projects. They’re the ones making smart, portfolio-level decisions and executing them with discipline.
This guide is built for people who have to make those decisions and live with the results — CTOs, enterprise architects, digital transformation leads, and business executives who need more than high-level slides. We’ll start by getting clear on why modernization matters in concrete terms. Then we’ll cover how to assess what you actually have. We’ll break down the practical strategies available (the well-known “Rs” framework). We’ll give you a straightforward way to choose among them. And in later sections we’ll move into how to actually deliver without the usual chaos.
The goal is simple: help you move from “we know we need to do something” to a clear plan you can defend to your board and execute with confidence.
Why Modernize? The Business and Technical Imperative
Let’s be direct. The single biggest reason most organizations modernize is cost — but not in the way people usually think.
A large portion of IT budgets in mature companies still goes to keeping legacy systems running: patching, workarounds, emergency fixes, and the slow accretion of technical debt. That money doesn’t create new revenue or better experiences. It just prevents yesterday’s problems from becoming today’s disasters. When you modernize thoughtfully, you typically free up 30–50% of infrastructure and maintenance spend over time, sometimes more. That money can go back into growth initiatives instead of survival mode.
But cost is rarely the only driver — and often not even the most important one.
Business agility and speed
Markets move faster than they used to. A competitor can launch a new service or pricing model in weeks. If your core systems require months of analysis, coding, testing, and deployment just to make a modest change, you’re structurally disadvantaged. Modern architectures — whether microservices, event-driven designs, or well-integrated platforms — let teams release smaller increments more frequently with lower risk. That changes the conversation from “what can we afford to change this quarter” to “what should we test next week.”
Innovation and new capabilities
Want to add intelligent automation, personalized customer experiences, predictive maintenance, or real-time fraud detection? Legacy systems are often closed boxes. Data is trapped in silos. There are no clean APIs. Adding anything meaningful requires expensive custom integration layers that become their own maintenance burden. Modernized applications expose data and functionality in usable ways. They make AI and advanced analytics practical rather than heroic.
Risk and resilience
Old systems are harder to secure. They often run on unsupported operating systems or languages. Knowledge about how they actually work walks out the door when experienced people retire. A single failure can cascade. Modern systems give you better observability, automated scaling, faster recovery, and clearer audit trails. In regulated industries — finance, healthcare, critical infrastructure — this isn’t optional anymore.
Talent and culture
This one is under-appreciated. Good engineers and architects don’t want to spend their careers maintaining 20-year-old codebases with poor documentation and fragile dependencies. Organizations that modernize tend to attract and retain stronger technical teams. The work becomes more interesting, and career paths feel more future-proof.
Customer expectations
Whether you serve consumers or other businesses, expectations have shifted. People expect digital interactions to be fast, always available, and increasingly intelligent. Legacy systems that were designed for batch processing or limited user loads struggle here. Modernization often delivers the biggest visible improvements in customer-facing experiences.
The risks of staying still are real and compounding. Every year you delay, the gap between what your systems can do and what the business needs tends to widen. Technical debt compounds. Security exposure grows. Talent becomes harder to find for the old stack. And competitors who have already modernized move further ahead.
None of this means every application needs a dramatic overhaul. Some should be left alone or retired. The point is to make those choices consciously rather than by default.
Assessing Your Current Application Landscape
You can’t choose a strategy intelligently if you don’t understand what you’re working with. The assessment phase is where many modernization programs succeed or fail before they even begin.
Start with a proper inventory. This sounds basic, but it’s surprising how many organizations have incomplete pictures. You need to know every application that matters — core systems, supporting tools, integrations, data flows, and even the “shadow” processes that live in spreadsheets or unofficial scripts. Automated discovery tools from cloud providers and specialized vendors can map dependencies and usage patterns quickly. Combine that with interviews and workshops. The goal is a living inventory, not a one-time spreadsheet that goes stale.
For each significant application, evaluate several dimensions:
- Business value: How directly does it support revenue, operations, compliance, or customer experience? Who uses it and how often? What happens to the business if it’s unavailable for an hour, a day, or a week?
- Technical health: Age of the technology stack, complexity of the architecture, quality and maintainability of the code, level of coupling and dependencies, performance characteristics, and known issues or risks.
- Data considerations: Where does the data live? How clean and accessible is it? What are the compliance, privacy, or sovereignty requirements?
- Risk and complexity: How difficult would it be to change or replace this system? Are there single points of failure or institutional knowledge held by only a few people?
- Future trajectory: Does this application need to support significant new functionality, scale, or integration in the next few years?
A simple but powerful way to prioritize is a 2×2 matrix. One axis is business value or criticality. The other is technical complexity or risk. Applications that are high-value and high-complexity usually deserve early focus — they’re the ones holding the business back the most. Low-value, low-risk applications are often good candidates for retirement or minimal treatment. Quick wins in the low-complexity, medium-value quadrant can build momentum and credibility for bigger efforts.
Don’t try to assess the entire portfolio in exhaustive detail at the start. Begin with the top 20–50 applications by business impact. Use cross-functional workshops that include business owners, not just technical people. The conversations that happen in these sessions are often as valuable as the output itself — they surface assumptions, political realities, and hidden dependencies.
Many organizations discover during assessment that a surprising number of applications are lightly used or redundant. Retiring or consolidating even a few of these can free up meaningful resources and reduce risk immediately.
The output of this phase should be clear: a prioritized list of applications, with enough understanding of each one to evaluate modernization options intelligently. You don’t need perfect data. You need enough clarity to make good decisions and defend them.
The Modernization Strategies: Understanding Your Options
Once you understand your landscape, you need a clear menu of approaches. The industry standard framework is known as the “7 Rs” (sometimes presented as 6 Rs). These categories help teams think systematically rather than defaulting to the same approach for everything.
Here’s what each one actually means in practice:
Retain (or Revisit):
Keep the application as it is, at least for now. This makes sense when the system is stable, low-change, adequately supported, and not a major constraint on the business. You might still invest in better monitoring or minor operational improvements, but you’re consciously choosing not to modernize it at this time. It’s a valid strategic decision, not a failure of imagination.
Retire:
Decommission the application entirely. Many portfolios contain redundant functionality, systems that were built for one-off needs and never retired, or tools whose users have moved on. Retiring something removes ongoing maintenance, licensing, and security exposure. It requires planning for data archival, user transition, and any downstream dependencies, but the long-term savings and risk reduction are often substantial.
Rehost (Lift-and-Shift):
Move the application to a modern infrastructure environment — usually the cloud — with minimal or no changes to the code or architecture. You’re essentially taking what exists and running it on virtual machines, containers, or cloud infrastructure. This is often the fastest way to gain benefits like elasticity, pay-as-you-go economics, and improved disaster recovery. It’s a good fit when speed matters more than deep optimization, or when you want to exit a data center quickly. The main trade-off is that you may still carry forward some inefficiencies of the original design.
Replatform (Lift-Tinker-Shift):
Similar to rehost, but with targeted changes that take advantage of the new environment. Common examples include moving a database to a managed cloud service, containerizing parts of the application, or adopting cloud-native logging and monitoring. You get more value than pure rehost with moderate additional effort. This is often a pragmatic middle path for applications that can benefit from incremental improvements without a full rewrite.
Refactor (or Rearchitect):
Restructure the existing code and architecture to improve its internal design, maintainability, and alignment with modern patterns — while preserving the external behavior users depend on. This frequently involves breaking monolithic applications into smaller, more loosely coupled services, improving modularity, and adopting better separation of concerns. It requires more development skill and time than rehosting or replatforming, but it delivers lasting improvements in agility, scalability, and the ability to evolve the system over time.
Rebuild (Rewrite):
Design and construct a new application from the ground up, often using contemporary languages, frameworks, cloud-native patterns, and architectures that fit current and anticipated needs. This is the highest-effort option and carries more risk, but it’s appropriate when the legacy system’s constraints are too severe, when major new functionality is required, or when the business case justifies a clean break. Many successful rebuilds use iterative, incremental approaches rather than big-bang replacements.
Repurchase (Replace):
Stop maintaining a custom system and adopt a commercial off-the-shelf (COTS) or software-as-a-service (SaaS) solution instead. This works well for functions that are not core differentiators — think HR systems, certain CRM capabilities, or standard financial processes. You trade customization for speed, reduced maintenance, and access to continuous innovation from the vendor. The main work shifts to data migration, process adaptation, and integration.
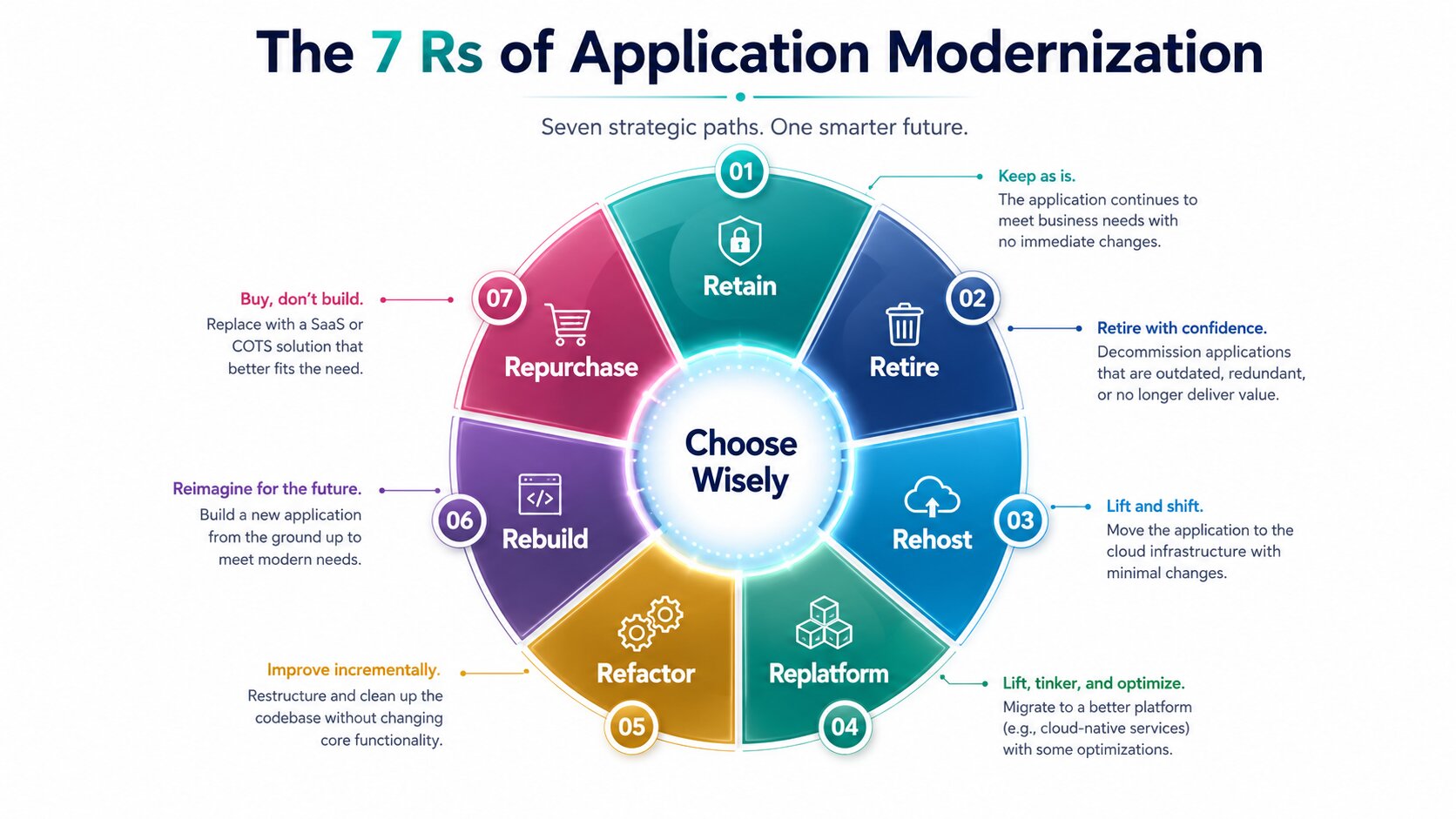
In practice, the smartest organizations apply different Rs to different parts of their portfolio. A global manufacturer might rehost some reporting and analytics workloads, refactor core production planning systems, repurchase commodity supply-chain functions, and retain a few highly specialized legacy tools that still work well. The framework prevents the common mistake of forcing every application through the same transformation.
Choosing the Right Strategy: A Decision Framework
Knowing the options is one thing. Deciding which ones to use — and in what order — is where judgment and structure matter most.
The best decisions start with clarity on objectives. Are you primarily trying to reduce cost and risk quickly? Gain agility and enable new digital capabilities? Exit a data center by a hard deadline? Different goals naturally favor different strategies. Rehost and replatform tend to win on speed and lower immediate risk. Refactor and rebuild win on long-term flexibility and innovation potential. Retire and repurchase can deliver fast cost and complexity reduction.
For each application (or logical group), evaluate the realistic options against several practical criteria:
- Business alignment and urgency: How well does this option support the outcomes the business actually cares about? How time-sensitive is the need?
- Technical suitability: Does the current architecture and codebase lend itself to this approach? Highly coupled, poorly documented systems are much harder (and riskier) to refactor or rebuild than well-structured ones.
- Effort, cost, and timeline: Be realistic about development, testing, data migration, integration, training, and change management. Include ongoing operational costs, not just the project cost.
- Risk profile: What are the main things that could go wrong — data issues, downtime, user adoption, integration breakage? How confident are you in your ability to mitigate them?
- Organizational readiness: Do you have the skills, capacity, and cultural willingness to succeed with this approach? For more ambitious strategies, you may need to invest in training, coaching, or external partners.
- Future flexibility: Will this choice make it easier or harder to adapt the system over the next 3–5 years as needs evolve?
A useful technique is to score the viable options on these dimensions using a simple weighted framework. Give higher weight to the factors that matter most in your context (business value and risk often deserve heavy weighting). Run the scoring in workshops with the right mix of business and technical stakeholders. The conversation that produces the scores is often more valuable than the numbers themselves.
There are predictable pitfalls to avoid. One is letting technology fashion drive the decision — choosing to refactor everything because microservices are trendy, even when simpler options would deliver better results faster. Another is underestimating the people and process side of change. A technically perfect migration can still fail if users aren’t brought along or if operations teams aren’t prepared. A third is trying to do too much at once. Starting with well-chosen pilots builds confidence, surfaces real issues early, and creates internal advocates.
The organizations that choose well treat this as a portfolio decision, not a collection of isolated projects. They sequence work to manage risk and cash flow. They revisit choices periodically as they learn more. And they stay focused on the business outcomes rather than the technology itself.
This decision framework turns a potentially overwhelming set of possibilities into a manageable, defensible plan. It also creates the alignment you’ll need when the inevitable challenges of execution appear.
Execution Playbook: Step-by-Step Implementation
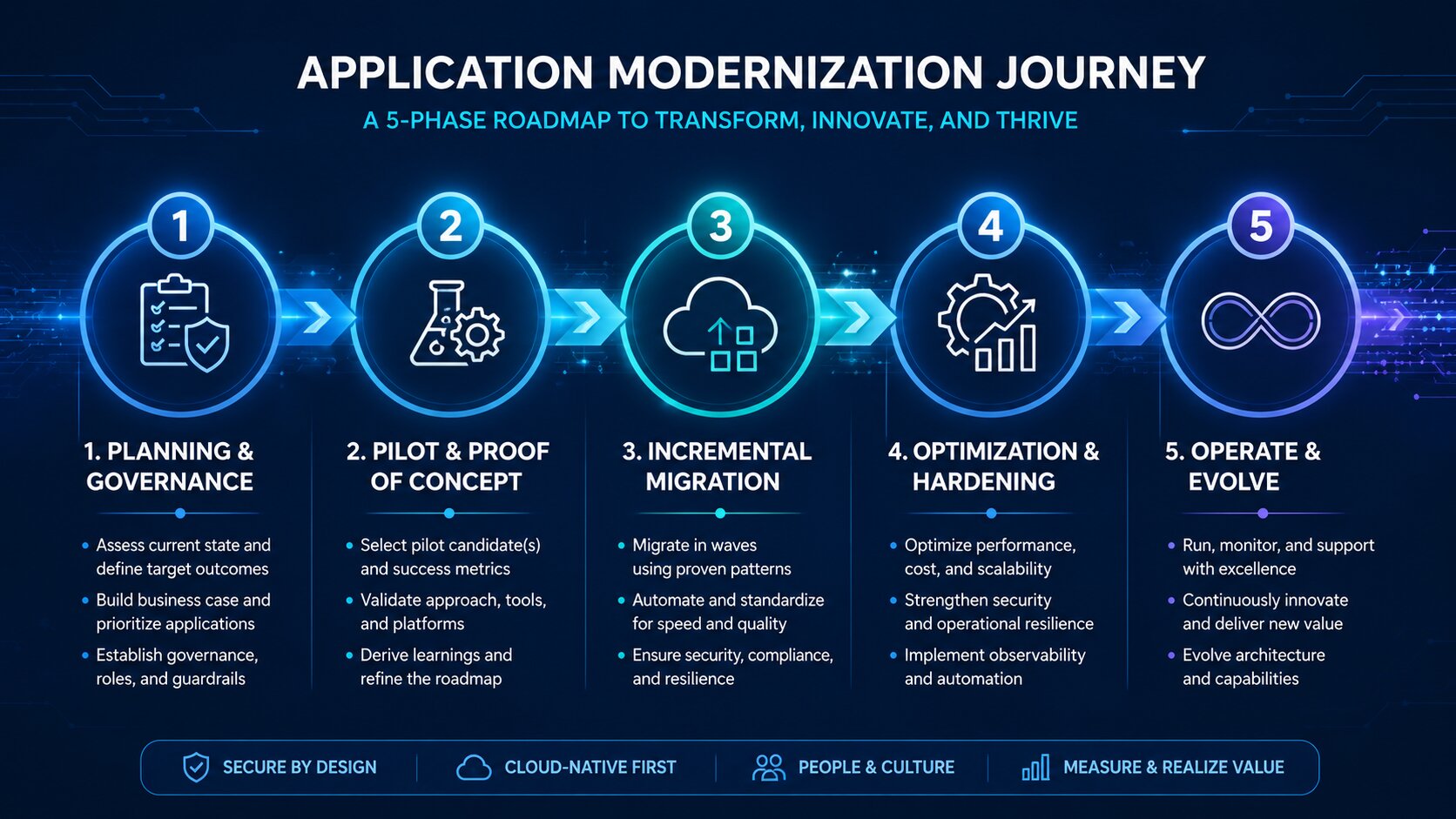
Strategy without disciplined execution is just wishful thinking. This is where many modernization programs lose momentum or deliver disappointing results. The organizations that succeed treat execution as a series of deliberate, manageable phases rather than one massive project.
Phase 1: Planning and Governance
Start by locking in clear scope, success metrics, and decision rights. Who owns the outcomes? How will trade-offs be made when (not if) surprises appear? Establish a lightweight governance structure — often a steering group with business and technical representation that meets regularly but doesn’t micromanage. Define the operating model for the modernized applications: who will run them, how will they be funded, and how will ongoing evolution be handled?
Create a realistic roadmap that sequences work across the portfolio. Not everything can or should happen at once. Prioritize based on the assessment you already did: quick wins for momentum, high-value/high-risk applications for focused attention, and foundational platforms that enable later work.
Phase 2: Pilot and Proof of Concept
Pick one or two applications (or a bounded slice of a larger one) and prove the chosen strategy works in your environment. A pilot should be meaningful enough to generate real learning but contained enough that failure doesn’t sink the program. Measure what matters: technical performance, developer productivity, cost impact, and user or business feedback.
Pilots also surface organizational issues early — integration friction, skills gaps, resistance to new ways of working. Fix those before you scale.
Phase 3: Incremental Migration and Modernization
This is usually the longest phase. The Strangler Fig pattern is invaluable here: gradually replace parts of the legacy system with new functionality while keeping the overall system running. New capabilities are built alongside the old ones, and traffic or usage is shifted over time. This reduces risk dramatically compared with big-bang cutovers.
Use modern delivery practices from day one: continuous integration and continuous delivery (CI/CD) pipelines, automated testing, infrastructure as code, and feature flags or canary releases. These practices aren’t optional extras; they’re what make incremental change safe and sustainable.
Data migration deserves special attention. It’s often the riskiest part. Plan for iterative data movement, validation, and rollback capabilities. Don’t assume “we’ll figure out the data later.”
Phase 4: Optimization and Hardening
Once core functionality is running in the new environment, focus on performance, cost, reliability, and security. Cloud environments reward ongoing tuning — rightsizing resources, adopting managed services where they make sense, implementing proper observability, and automating operational tasks. This phase often delivers surprising additional value that wasn’t obvious during initial migration.
Phase 5: Operate and Evolve
Modernization isn’t a project with an end date. It’s a shift to a product mindset. The teams that own the modernized applications should have clear ownership, funding, and incentives to keep improving them. Establish feedback loops from production usage back into the roadmap. Treat technical debt as something to manage continuously rather than let it accumulate again.
Throughout execution, pay attention to the human side. New tools and architectures require new skills. Invest in training, coaching, and pairing. Communicate early and often with all stakeholders — not just progress reports, but honest updates on challenges and what you’re learning. Resistance usually comes from uncertainty; transparency reduces it.
The most successful programs I’ve seen maintain a rhythm: regular demos of working software, transparent risk reviews, and a bias toward small, frequent deliveries over large, infrequent ones. That rhythm builds confidence and keeps the organization engaged.
Technologies, Tools, and Architectures for Success
Technology choices should follow strategy and constraints, not drive them. Still, certain patterns and capabilities consistently prove valuable in modernization work.
Cloud Platforms as the Foundation
Whether you choose AWS, Microsoft Azure, Google Cloud, or a hybrid/multi-cloud approach, the major platforms now offer mature services that remove undifferentiated heavy lifting. Managed databases, serverless compute, container orchestration, messaging, and AI/ML services let teams focus on business logic rather than infrastructure plumbing. The key is to use these services intentionally rather than simply lifting existing patterns into the cloud.
Containerization and Orchestration
Docker and Kubernetes have become near-standard for many modernization efforts. They provide consistency across environments, better resource utilization, and easier scaling. Not every application needs to become fully containerized immediately, but containerizing well-bounded services is often a high-ROI step that improves portability and operational characteristics.
Microservices and Event-Driven Architectures
Breaking large monolithic applications into smaller, independently deployable services improves team autonomy and release velocity. Event-driven designs reduce tight coupling and make systems more resilient and easier to evolve. These patterns require discipline around service boundaries, data ownership, and observability — but when done well, they pay dividends for years.
Serverless and Platform Abstractions
For many workloads, serverless options (functions, managed containers, databases) eliminate even more operational burden. They shine for spiky or unpredictable loads and for teams that want to minimize infrastructure management. The trade-off is usually some loss of control and potential vendor lock-in, so evaluate fit carefully.
AI and Automation in the Modernization Process Itself
This is an area that has advanced rapidly. Tools can now analyze large codebases, suggest refactoring opportunities, generate documentation, and even assist with test creation or data mapping. Used thoughtfully, they accelerate assessment and certain refactoring tasks. They don’t replace skilled architects and developers, but they amplify their effectiveness.
Observability, Security, and Data
Modern systems need excellent observability from the start — metrics, logs, traces, and meaningful alerts. Security should be designed in (zero-trust principles, automated scanning, secrets management) rather than bolted on later. Data modernization — moving to cloud-native databases, improving data quality, enabling real-time access — is often as important as the application code itself.
Practical Advice on Tooling
There’s no shortage of specialized tools for discovery, migration, refactoring, and governance. Evaluate them against your specific constraints rather than adopting whatever is most heavily marketed. Many teams succeed with a relatively small, well-integrated set of tools rather than a sprawling toolchain. Focus on automation that reduces toil and risk, not on tools for their own sake.
The architectures that age well tend to have clear boundaries, explicit contracts between components, good observability, and the ability to evolve one part without breaking everything else. Those qualities are more important than any single technology choice.
Overcoming Challenges and Managing Risks
Every modernization effort encounters friction. The difference between success and expensive disappointment usually comes down to how honestly and proactively those challenges are handled.
Scope Creep and Unrealistic Expectations
It’s easy for stakeholders to want “everything modernized” on an aggressive timeline with limited budget. Counter this with clear scope boundaries, phased delivery, and regular re-prioritization based on value delivered. Celebrate what’s working and be transparent about what’s taking longer than expected.
Skills Gaps and Team Capacity
Modern architectures and delivery practices require different skills than maintaining legacy systems. Some people will need training and support; others may need new roles or partners to fill gaps. Ignoring this is one of the fastest ways to stall progress. Invest early in capability building — it pays off faster than most leaders expect.
Organizational Resistance and Change Fatigue
People get attached to familiar systems and ways of working. Some fear job loss or loss of control. Address this directly through communication, involvement in decision-making, and demonstrating early wins that make people’s jobs better rather than harder. Change management isn’t a soft skill here — it’s a core success factor.
Data and Integration Complexity
Data migration and integration with surrounding systems are frequently underestimated. Plan for iterative approaches, thorough validation, and the reality that some data quality issues will only surface during migration. Build in time and contingency for this work.
Security, Compliance, and Regulatory Requirements
Modernization can improve security posture, but it can also introduce new risks if not managed carefully. In regulated industries, involve compliance and security teams from the beginning. Document decisions and maintain auditability throughout.
Budget and Timeline Pressure
Modernization programs often face pressure to show results quickly while also being asked to do more with less. Use pilots and incremental delivery to generate early value and evidence. Be realistic in planning and build in buffers for the inevitable surprises. Track both leading indicators (delivery velocity, defect rates) and lagging ones (cost savings, business outcomes).
Hybrid and Multi-Cloud Realities
Many organizations end up with hybrid environments for good reasons — regulatory requirements, existing investments, or specific workload needs. Design for this rather than pretending everything will live in a single public cloud. Portability and consistent operational practices become even more important.
The programs that navigate these challenges best treat risk management as an ongoing discipline, not a one-time exercise. They maintain visibility into technical debt, integration points, and organizational health. They adjust course based on what they learn rather than clinging to original plans that no longer fit reality.
Real-World Case Studies and Lessons Learned
Abstract frameworks are useful, but concrete examples show how choices play out in practice.
One well-documented journey is Amazon’s evolution from a monolithic e-commerce application to a highly distributed, service-oriented architecture. Early on, the company faced scaling challenges and slow release cycles. By systematically identifying bounded contexts and extracting services, they gained the ability to innovate independently across teams. The process took years and involved many iterations, but it created the foundation for the scale and speed Amazon is known for today. Key lesson: start with clear service boundaries and be willing to revisit them as understanding deepens.
In financial services, several global banks have taken a more measured approach to core banking and transaction systems. One European institution rehosted large portions of its less critical workloads to gain immediate infrastructure benefits and exit aging data centers. For core transaction processing, they chose a phased refactor — gradually introducing new services around the legacy core using the Strangler Fig pattern. This allowed them to meet regulatory deadlines while building modern capabilities incrementally. The lesson here: different parts of the portfolio genuinely need different strategies, and sequencing matters.
A manufacturing company with operations across multiple continents faced aging supply-chain and production planning systems. Rather than a single massive program, they identified a high-pain, high-value slice (order-to-cash in one region) and rebuilt it using modern cloud-native patterns and event-driven integration. The success of that pilot created internal demand and confidence. Subsequent phases reused patterns and components, accelerating later work. Lesson: well-chosen pilots compound — they deliver value and create reusable assets and organizational learning.
In the public sector, modernization efforts often emphasize risk reduction and citizen experience alongside cost. One agency consolidated multiple redundant citizen-facing applications by repurchasing core capabilities from a proven platform and integrating them with retained specialized systems. This reduced the number of systems they had to maintain while improving service consistency. The key was honest assessment of where customization was truly necessary versus where standard processes would suffice.
Across these examples, common patterns emerge. Successful efforts combine clear business outcomes with technical pragmatism. They invest in the “soft” aspects — communication, skills, governance — as much as the technology. They deliver value in increments rather than waiting for a perfect end state. And they treat modernization as an ongoing capability rather than a one-time project.
Future Trends and Sustaining Modernization
Modernization in 2026 already looks different from even a few years ago, and the trajectory is clear.
AI is moving from an add-on to a core part of both the modernization process and the resulting systems. Tools that can understand and refactor code at scale, generate tests, or suggest architectural improvements are becoming practical. At the same time, modernized applications are increasingly expected to support AI workloads — real-time inference, model serving, and data pipelines that feed them. Organizations that modernize with AI in mind will have an advantage.
Platform engineering is gaining traction as a way to scale modernization efforts. Instead of every team building their own deployment pipelines, observability stacks, and infrastructure patterns from scratch, internal platforms provide paved roads that teams can use safely and productively. This reduces duplication and accelerates consistent adoption of good practices.
Edge computing and distributed architectures are becoming more relevant for certain workloads — manufacturing, retail, logistics, and anything requiring low latency or operation in disconnected environments. Modernization strategies increasingly need to account for hybrid edge-cloud designs.
Sustainability considerations are also entering the conversation. More efficient architectures and right-sized infrastructure can reduce energy consumption and carbon footprint, which matters for both cost and corporate responsibility goals.
The most important long-term trend is the shift from “modernization project” to “modernization capability.” Organizations that treat this as a one-time event eventually find themselves with a new generation of legacy systems. Those that build the muscle to continuously assess, decide, and evolve stay ahead.
Sustaining momentum requires deliberate investment: ongoing skills development, lightweight governance that enables rather than blocks, clear ownership of applications as products, and regular portfolio reviews that surface when new modernization opportunities or retirements make sense.
Conclusion and Action Plan
Application modernization, done well, is one of the highest-leverage investments an organization can make. It reduces cost and risk while unlocking agility, innovation, and better experiences. The difference between transformative results and expensive disappointment lies in clear-eyed assessment, thoughtful strategy selection, and disciplined, incremental execution.
The framework in this guide — understand your landscape, choose from proven options using a structured decision process, execute in phases with modern practices, manage risks proactively, and build the capability to keep evolving — has been proven across industries and regions. It isn’t flashy, but it works.
If you’re just getting started, here’s a practical 30/60/90-day starter plan:
First 30 days:
Complete a focused assessment of your top 10–20 applications. Run a workshop to align business and technical stakeholders on objectives and priorities. Identify 1–2 pilot candidates.
Next 30 days (days 31–60):
Choose strategies for the pilots using the decision framework. Stand up the pilot team, define success metrics, and begin implementation. Establish basic governance and communication rhythms.
Final 30 days (days 61–90):
Deliver working increments of the pilots. Capture lessons learned. Build the initial roadmap for the next wave of applications. Secure the resources and organizational alignment needed to scale.
Modernization is a journey, not a destination. The organizations that treat it that way — making steady, informed progress while delivering value along the way — are the ones that pull ahead and stay ahead.
The path is clearer than it often feels. Start with honest assessment, choose deliberately, execute incrementally, and keep learning. The results will speak for themselves.